Squid: Unterschied zwischen den Versionen
Admin (Diskussion | Beiträge) K (1 Version) |
Admin (Diskussion | Beiträge) |
||
| Zeile 110: | Zeile 110: | ||
{|Border=1 Cellpadding=3 | {|Border=1 Cellpadding=3 | ||
| − | | | + | |Neighbours |
|Dies sind alle Proxies, die ein Proxy kennt und mit denen er kommuniziert. | |Dies sind alle Proxies, die ein Proxy kennt und mit denen er kommuniziert. | ||
|- | |- | ||
Version vom 17. Juli 2009, 06:43 Uhr
Einleitung
Der Einsatz von Computernetzwerken in Firmen jeglicher Größe hat in den letzten Jahren stark zugenommen. Dabei haben viele Firmen neben dem lokalen Netz auch eine Anbindung an ein öffentliches Netz und damit meist auch Zugang zum Internet.
Damit verbindet sich ein weltweiter Ausbau dieses Netzes und ein steigendes Angebot an Serviceleistungen, die über das Internet angeboten werden. Als neuere Technologie sei hier nur die Internettelefonie genannt. Dies bedeutet allerdings auch, daß die zu übertragenden Datenmengen ständig zunehmen, was zu Engpässen und langen Übertragungszeiten führt.
Für die Unternehmen bedeuten die zunehmenden Datenmengen aber auch in erheblichem Maße zunehmende Kosten. Deshalb sind Technologien gefragt, die dabei helfen können, diese Datenmengen und damit auch die Kosten entsprechend einzuschränken.
Die Anbindung an öffentliche Netze bedeutet aber auch immer ein Risiko, da es selten möglich ist, eine Verbindung nur in eine Richtung aufzubauen. Dadurch bieten sich Angriffspunkte, die von einigen Leuten ausgenutzt werden, um an Daten zu kommen oder Schaden in dem Netz anzurichten. Auch hier herrscht großer Bedarf an neuen Lösungen, um einen Kom-promiß zwischen Sicherheit und Kommunikation zu finden.
Im Internetbereich bietet sich für beide Gebiete der Einsatz von Proxy- Agenten an. Proxy ist das englische Wort für Stellvertreter. Und genau diese Aufgabe soll ein Proxy-Agent übernehmen.
Gerade bei großen Netzwerken macht sich der Einsatz eines solchen Proxy- Agenten positiv bemerkbar, da er neben einer Verringerung der Netzlast im und zum öffentlichen Netz auch einen Performancegewinn innerhalb des lokalen Netzes bewirkt.
Einsatz von Proxy-Servern
Einsatzgebiete und Funktionalität
Mit der immer größer werdenden Vernetzung und Globalisierung wachsen auch immer mehr die Probleme der Betreiber von lokalen Netzen. Einerseits müssen die Kosten für den Datentransfer mit dem Internet gering gehalten werden und zum anderen stellt die Anbindung an ein öffentliches Netz auch immer einen Angriffspunkt dar.
Die Gefahren sind dabei recht vielfältig. Zum einen ist es in größeren Netzwerken dem Administrator meist nicht möglich, die Konfiguration aller Computer ständig zu überwachen und nach Sicherheitslücken zu suchen, zumal oft auch die notwendige Software recht teuer ist oder vorhandene sich nicht so verhält, wie man es gerne hätte. Zweitens ist eine Verbindung ins Internet auch immer mit Datentransfer in beiden Richtungen verbunden, wodurch von außen ein Angreifer durch getarnte Datenpakete in das lokale Netz eindringen und dort Schaden anrichten kann. Hier seien Computerviren in ihren vielen Erscheinungsformen erwähnt. Zum Dritten stellen die Anwender selber eine gewisse Gefahr dar, indem sie den Zugang zum Internet mißbräuchlich oder unbeabsichtigt nutzen, was sehr hohe Kosten verursachen kann.
Dieses Problem läßt sich im Internet mit Hilfe eines Proxy-Servers lösen. Proxy ist das englische Wort für Stellvertreter. Wie der Name schon vermuten läßt, tritt ein Proxy-Server als Stellvertreter auf. Will nun ein Client im lokalen Netz ein Dokument aus dem Internet anfordern, muß er die Anfrage an den Proxy-Server leiten, der dann die Anfrage an den Server weiterleitet. Daraus wird ersichtlich, daß ein Proxy-Server zwei Gesichter haben muß. Nach innen zum Client muß er den Internetserver vertreten und nach außen wiederum stellt er sich als Client dar. Dies hat aus Sicht der Sicherheit noch den weiteren Vorteil, daß nach außen hin nur der Proxy-Server sichtbar ist und das Netz dahinter für einen möglichen Angreifer unsichtbar bleibt. Ein Proxy muß daher beide Seiten der Kommunikation beherrschen. Wie so eine Kommunikation aussieht, ist in
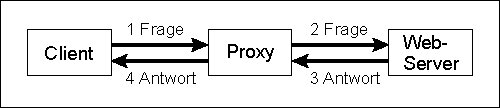

Caching
Die Übertragungsraten im Internet sind oft sehr gering, da bestimmte Leitungen, insbesondere transkontinentale, stark belastet sind. Dadurch kann es wiederum vorkommen, daß die Leitung nach außen ausgelastet ist und durch lange Wartezeiten die Kosten der Übertragung in die Höhe gehen.
Ein Ansatzpunkt, die Auslastung und Performance zu optimieren, ist das Zwischenspeichern von Objekten. Dies macht im Internet Sinn, da es oft vorkommt, daß ein Dokument in einem lokalen Netz mehrmals von verschiedenen Clients angefordert wird. Dieses Zwischenspeichern oder Caching von Dokumenten übernimmt ebenfalls der Proxy-Server, der deshalb auch oft als Proxy-Cache bezeichnet wird. Fordert ein Client ein Dokument von einem Server an, so leitet der Proxy die Anfrage an den Server weiter. Dieser liefert das angeforderte Dokument an den Proxy, der es dann an den Client weiter reicht und eine Kopie in seinem Speicher behält. Kommt nun von einem zweiten Client die Anfrage auf dasselbe Dokument, leitet der Proxy diese nicht an den Server weiter, sondern liefert das Dokument aus seinem Speicher direkt an den Client
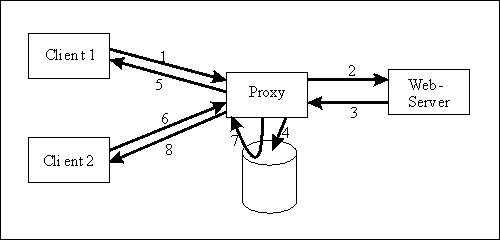

Dies macht deutlich, welche Vorteile ein Proxy-Cache bietet. Zum einen wird die externe Leitung nicht unnötig mit dem mehrmaligen Holen desselben Objektes belastet, es fallen also für die Übertragung keine Kosten an, und außerdem wird die Performance für die Clients im LAN deutlich erhöht. Untersuchungen haben gezeigt, daß die Trefferquoten beim Einsatz eines Proxy-Caches bis zu 50% sind, also fast jede zweite Anfrage nach außen einspart.
Sinnvolles Caching
Um ein sinnvolles Caching zu erreichen, müssen gewisse Voraussetzungen gegeben sein. Diese fangen damit an, daß die Maschine, auf der ein solcher Proxy-Server läuft von der Hardware entsprechend ausgestattet sein muß. Je nach der Anzahl der Clients, die den Proxy benutzen muß die Leistungsfähigkeit des Rechners ausgelegt sein, damit auch genügend Anfragen gleichzeitig bearbeitet werden können. Um die Trefferquote auf die im Cache abgelegten Objekte zu erhöhen, sollte auch entsprechende Speicherkapazität vorhanden sein. Diese sollte auf jeden Fall mehrere Gigabyte umfassen. Da aber in der letzten Zeit die Preise für Festplattenspeicher enorm nach unten gegangen sind, sollte dies heute kein größeres Problem mehr darstellen. Die Hardwarevoraussetzungen alleine machen aber noch keinen guten Proxy-Cache aus, sondern bilden nur eine solide Grundlage. Ein viel größeres Problem ist es, daß die Lebensdauer von Web-Seiten sehr unterschiedlich ist. Dadurch kann nie mit Sicherheit bestimmt werden, wann sich eine Seite ändert und dadurch veraltet ist und aus dem Cache gelöscht, bzw. beim Server neu angefordert werden soll. Es kann also immer vorkommen, daß der Cache ein veraltetes Dokument an den Client liefert. Durch verschiedene Strategien wird versucht, dieses Manko so weit wie möglich auszugleichen. HTTP bietet dazu zwei Möglichkeiten: Last-Modified und Expires. Mit der Antwort des Servers werden diese Information an den Proxy mitgeteilt. Mit Last-Modified wird angezeigt, wann das Dokument das letzte mal geändert wurde. Mit der Angabe Expires erhält der Client (in diesem Falle der Proxy) Informationen, wann er das Dokument als veraltet ansehen soll und vom Server neu anfordern muß. In einem HTML-Dokument werden diese Angaben im Header generiert. Dazu wird das META-Element benutzt. Die Informationen sehen dann wie im folgenden Beispiel aus:
<META HTTP-EQUIV=“Last-Modified“ CONTENT=“Thu Jan 1 12:00:00 GMT DST 1998“>
<META HTTP-EQUIV=“Expires“ CONTENT=“Thu Dec 31 12:00:00 GMT DST 1998“>
Allein die Expires-Angabe würde reichen, um den Cache in dieser Hinsicht zu optimieren. Jedoch sind diese Angaben optional und werden sehr selten eingesetzt. Außerdem ist es oft schwierig die Lebensdauer einer Web-Seite vorauszusagen. Daher sind die meisten Web-Seiten einfach so lange gültig, bis der Autor eine neue Version erstellt. Anders sieht es bei Last-Modified aus. Diese Angabe findet sich zwar selten explizit in HTML-Dokumenten, jedoch trägt jedes Dokument als Datei einen Zeitstempel, welcher vom Server dann als Last-Modified-Header mitgeliefert wird.
Die Proxy-Server wenden damit ein einfaches Verfahren ein, um die Lebensdauer eines Dokumentes zu „erraten“. Dabei wird zugrunde gelegt, daß die Wahrscheinlichkeit recht gering ist, daß ein recht altes Dokument in den nächsten Stunden geändert wird. Bei einem Dokument, welches dagegen erst vor kurzem geändert wurde, ist die Möglichkeit einer baldigen Aktualisierung eher vorhanden.Sofern ein Objekt keinen Expires-Header aufweist, erzeugt der Proxy-Server mit Hilfe des Last-Modified-Headers ein künstliches Verfallsdatum. Dazu bestimmt er das Alter der Datei und schlägt einen Prozentsatz dazu, der bei der Konfiguration des Proxy-Servers eingetragen wird (Direktive refresh_pattern), und holt frühestens nach Ablauf dieser Zeit von sich aus das Dokument erneut vom Server.
Ist beispielsweise ein Dokument zum Zeitpunkt der ersten Anfrage des Proxies bereits 150 Tage alt und der Prozentsatz aus der Konfiguration ist 20%, so vergehen weitere 30 Tage, bis der Proxy-Server eine erneute Anfrage an den Originalserver stellt.
Um dies weiter zu optimieren wird das Dokument nur dann übertragen, wenn die Version auf dem Originalserver wirklich neuer ist, als die im Cache gespeicherte. Dazu schickt der Proxy eine Anfrage an den Originalserver, in der nur der Zeitstempel der Datei enthalten ist. Der Server vergleicht nun den empfangenen Zeitstempel der angeforderten Datei und sendet diese nur dann vollständig zurück, wenn sie jünger ist, als die im Proxy-Cache hinterlegte Kopie. Im anderen Falle erhält der Proxy nur eine kurze, aus HTTP-Headern bestehende Antwort, die signalisiert, daß keine Änderung stattgefunden hat. Der Proxy registriert dies und errechnet ein neues Verfallsdatum.
Neben diesen statischen Objekten, die eine gewisse Lebensdauer haben, gibt es aber auch dynamische Objekte, bei denen eine Zwischenspeicherung nicht angebracht ist. Dies sind beispielsweise HTML-Seiten, die ein CGI-Skript für Datenbankabfragen enthalten oder Seiten, die eine Berechtigung verlangen.
Es kann von beiden Seiten erzwungen werden, daß ein Objekt nicht im Cache gespeichert wird. Auf Seiten des Proxy-Servers erfolgt dies durch eine Einstellung in der Konfiguration. Damit ist es möglich, daß Seiten, die bestimmte Elemente (z.B. cgi-bin, ?, o.ä.) im URL enthalten nicht gespeichert werden. Dies kann man auch für ausgewählte Domänen angeben, was dann sinnvoll ist, wenn sich der Cache in einem Netz befindet, in dem selbst Web-Seiten angeboten werden.
Befindet sich beispielsweise der Proxy-Cache in dem Netz der Domäne testdomain.de, womöglich sogar auf dem selben Rechner wie der Web-Server, so wäre es Unsinn, die Seiten, die dort angeboten werden in den Cache zu legen, da dies unnötig Speicher verbraucht. Von Seiten des Anbieters kann dies über den Einbau einer Authentisierung erfolgen. Dadurch wird bei der Abfrage eines Objektes nach einer Benutzerkennung und einem Paßwort gefragt. Diese Informationen und auch Seiten, die eine Identifikation verlangen, werden standardmäßig nicht vom Proxy gespeichert und müssen jedesmal neu vom Originalserver geholt werden.
Hierarchisches Caching
Bei einigen Proxy-Servern ist es möglich, die Größe des Caches anzugeben, welcher im Hauptspeicher des Rechners liegt. Übertragene Objekte werden dort eine gewisse Zeit gehalten, um schnellere Antwortzeiten zu erreichen, falls ein Objekt innerhalb kurzer Zeit von zwei verschiedenen Clients angefordert wird. Dabei kann meist über den Parameter TTL (Time-to-Live) die Zeitdauer angegeben werden, die ein Objekt maximal in diesem Cache gehalten wird.
Eine weitere Möglichkeit, die Performance zu erhöhen und geringere Antwortzeiten zu erhalten, ist das hierarchische Caching. Banal gesagt setzt man einen Proxy für den Proxy ein. Dadurch kann die Trefferquote auf Objekte nochmals verbessert werden. Dies macht besonders deshalb Sinn, da die Datenmengen, die über die bestehenden Leitungen übertragen werden, immer größer werden und es immer wieder zu Engpässen kommt, die lange Übertragungszeiten verursachen. Das hierarchische Caching führt dabei zu einer Entlastung. Damit die Proxy-Caches miteinander kommunizieren können, wurde ein spezielles Protokoll entwickelt, das ICP (Internet Caching Protocol). Dabei schicken Proxy-Caches für das gewünschte Objekt Anfragen an benachbarte und in der Hierarchie höher stehende Proxy-Caches. Ist das Objekt in einem dieser Caches vorhanden, wird es übertragen, andernfalls wird es vom Originalserver geholt. Da das ICP auf UDP basiert, ist es sehr schnell und bedeutet somit einen vertretbaren Performanceverlust, der durch eine erhöhte Trefferquote mehr als ausgeglichen wird.
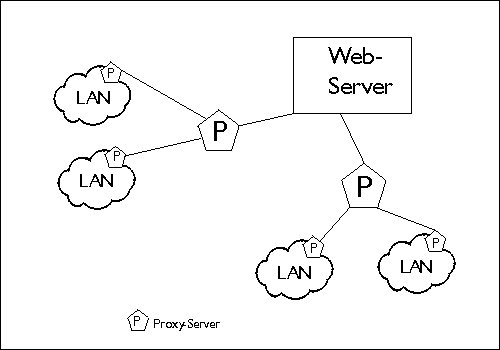

Begriffe
| Neighbours | Dies sind alle Proxies, die ein Proxy kennt und mit denen er kommuniziert. |
| Siblings | Die Geschwisterproxies. Sie liegen mit dem Proxy-Server auf einer Ebene. Siblings liefern in der Regel nur Objekte, die sie selbst im Cache haben, |
| Parents | Übergeordnete Proxies. Sie liefern Objekte die sie selbst im Cache haben und leiten Anfragen an den Originalserver weiter. |
Was ist Squid
Quelle: http://squid.nlanr.net/Squid/ bzw. http://www.squid-cache.org
Squid, ein Beispiel für einen Proxy-Server mit Cache-Mechanismus, ist aus der cached Software des Harvest Forschungsprojektes hervorgegangen. Informationen über Harvest sind auf folgender Webseite zu finden:
http://harvest.cs.colorado.edu/
Proxy-Systeme mit Cache-Mechanismen dienen meist der Performancesteigerung von Datentransfers, die bei langsamer Internet-Anbindung sehr groß sein kann, wenn Daten wiederholt angefordert werden.
Funktionsbeschreibung
Squid, der Internet Object Cache, ist jedoch mehr als ein einfacher Cache-Proxy. Durch die Unterstützung von Neighbor-Caches, die entweder als parent oder sibling verwendet werden, kann man einen Cache-Verbund aufbauen, der einen hohen Prozentsatz von Anfragen beantworten kann, ohne langwierige Internet-Zugriffe zu erfordern. Dieses Verfahren verwenden zum Beispiel einige der großen Internet-Provider (wie ECRC in München), um den Datentransfer wenn möglich auf der eigenen Netzwerkstruktur abzuwickeln und damit Kosten für externe Zugriffe zu umgehen.
Die Arbeitsweise von Squid ist einfach:
Eine Anfrage eines Clients wird zuerst auf die Zugriffsberechtigung untersucht, so kann man z.B. gewissen Rechnern einen Zugriff auf den Proxy ganz verbieten (siehe Konfiguration).
Es wird versucht, die gewünschten Daten im lokalen Cache zu finden. Sollte dies fehlschlagen, werden andere Proxies im Cache-Verbund (sofern vorhanden), abgefragt.
Sind die Daten vorhanden, wird ihre Aktualität geprüft. Sind die Daten veraltet, werden neue in den Cache geholt und an den Client weitergegeben. Bei aktuellen Daten wird das Neuladen übersprungen.
Sind die Daten nicht vorhanden, werden sie in den Cache geladen und an den Client weiter-gereicht. Wie lange Daten im Cache verbleiben, ist abhängig von der Konfiguration (siehe dort)
Eine Beschreibung der internen Abläufe wurde im Sinne der Übersichtlichkeit weggelassen.
Hilfe und Dokumentation zu Squid
Hilfe und Dokumentation im Internet:
| Die squid Website | http://www.squid-cache.org/Doc/ |
| squid IRC Channel | Server: irc.freenode.de -Channel: #squid |
| Mailingliste | squid-users@squid-cache.org |
Hilfe und Dokumentation im System
| Speziell zur Konfiguration | /etc/squid/squid.conf.default |
| Manualpage | man squid |
| Mitgelieferte Dokumentation | /usr/share/doc/squid/ |
Squid unter Ubuntu
Installation
root@zero:~# apt-get install squid3 squid3-common
Testen ob Squid läuft
root@zero:~# netstat -lntp | grep 3128 tcp 0 0 0.0.0.0:3128 0.0.0.0:* LISTEN 10743/(squid)
Start Skript
Das Startskript /etc/init.d/squid3 hat folgende Parameter
| start | Startet den Squid-Daemon |
| stop | Stoppt den Squid-Daemon |
| reload | Liest die Konfigurationsdatei neu ein |
| force-reload | das gleiche wie reload |
| restart | Stoppt den Deamon, falls er gestartet war und startet ihn wieder (synonym für stop und start) |
Squid Parameter
Gestartet werden kann Squid auch ohne das Startskript mit
/usr/sbin/squid3 [-cdhvzCDFNRVYX] [-s | -l facility] [-f config-file] [-[au] port] [-k signal]
Flogende Parameter können eingestellt werden:
| -a port | verändert die Portnummer für HTTP-Anfragen |
| -d level | Debug Output auf stderr ausgeben |
| -f file | gibt eine alternative Konfigurationsdatei zu /etc/squid3/squid.conf an |
| -k | mit dieser option können dem laufenden Squid verschiedene Steuersignale übergeben werden |
| -k reconfigure | die Konfigurationsdatei wird nochmals eingelesen |
| -k rotatate | schliesst und öffnet Dateien z.B. log_files |
| -k shutdown | squid wartet kurz und beendet die Verbindung und sich selbst.Mit shutdown_zeit wird Squid nach einer angegebenen Zeit beendet. |
| -k interrupt | sendet einen Interrupt worauf squid sofort abgebrochen wird ohne auf den Verlauf der Verbindungen zu achten. |
| -k kill | bricht squid sofort ab, die Verbindung und die log_files bleiben geöffnet |
| -k check | kontrolliert ob squid läuft |
| -s | erlaubt das Aufnehmen in die syslog |
| -u port | verändert die Portnummer des Internet Cache Protokoll ICP bzw. deaktiviert den Cache-Verbund mit der Portnummer 0 |
| -v | zeigt die aktuelle Squid Version |
| -z | richtet cache Verzeichnisse ein |
| -D | Squid führt normalerweise DNS Tests durch die hiermit abgestellt werden können |
| -F | wenn die swap.logs leer sind nützt squid die vollen Systemresourcen um sich um die Anfragen zu kümmern.Dies beschleunigt den Verarbeitungsvorgang |
| -N | der Serverprozess läuft nicht im Hintergrund |
| -V | Aktivierung des httpd Beschleunigungsmodus |
| -X | Full-Debug-Modus |
| -Y | Beschleunigt den ICP austausch bei niederwertigeren Caches |
Konfiguration
Squid wird mittels einer normalen Textdatei konfiguriert, die logisch in mehrere Teilbereiche unterteilt werden kann. Sie ist unter /etc/squid/squid.conf bzw. unter <prefix>/etc/squid.conf zu finden. Bei der Installation von Squid wird eine Default-Konfiguration erzeugt, die mit minimalen Änderungen bereits einen ersten Testlauf ermöglicht. Für die Ausnutzung der vollen Leistung von Squid sollte jedoch eine individuelle Anpassung erfolgen.
Alle Zeilen von squid.conf, die mit # beginnen, sind Kommentare bzw. nicht aktivierte Optionen. Als Minimalkonfiguration genügen die in Schnellstart beschriebenen Einstellungen. Für die genaue Syntax von Optionen sei ebenfalls auf squid.conf verwiesen, die folgenden Kapitel geben einen groben Überblick über die Möglichkeiten von Squid.
Da die Konfigurationsdatei in Ihrer Fülle und den ganzen Kommentaren sehr verwirrend ist kann man sie zunächst einmal auf das Wichtigste reduzieren. Vorher sollte die originale squid.conf gesichert werden:
cp squid.conf squid.conf.org grep "^[^#]" squid.conf.org > squid.conf
acl manager proto cache_object acl localhost src 127.0.0.1/32 acl to_localhost dst 127.0.0.0/8 acl SSL_ports port 443 acl Safe_ports port 80 # http acl Safe_ports port 21 # ftp acl Safe_ports port 443 # https acl Safe_ports port 70 # gopher acl Safe_ports port 210 # wais acl Safe_ports port 1025-65535 # unregistered ports acl Safe_ports port 280 # http-mgmt acl Safe_ports port 488 # gss-http acl Safe_ports port 591 # filemaker acl Safe_ports port 777 # multiling http acl CONNECT method CONNECT http_access allow manager localhost http_access deny manager http_access deny !Safe_ports http_access deny CONNECT !SSL_ports http_access allow localhost http_access deny all icp_access deny all htcp_access deny all http_port 3128 hierarchy_stoplist cgi-bin ? access_log /var/log/squid3/access.log squid refresh_pattern ^ftp: 1440 20% 10080 refresh_pattern ^gopher: 1440 0% 1440 refresh_pattern (cgi-bin|\?) 0 0% 0 refresh_pattern . 0 20% 4320 icp_port 3130 coredump_dir /var/spool/squid3
Zur besseren Übersicht unterteilen wir die Konfigdatei
#allgemeine sektion http_port 3128 access_log /var/log/squid3/access.log squid icp_port 3130 coredump_dir /var/spool/squid3 hierarchy_stoplist cgi-bin ? #refresh refresh_pattern ^ftp: 1440 20% 10080 refresh_pattern ^gopher: 1440 0% 1440 refresh_pattern (cgi-bin|\?) 0 0% 0 refresh_pattern . 0 20% 4320 #acl-sektion acl manager proto cache_object acl localhost src 127.0.0.1/32 acl to_localhost dst 127.0.0.0/8 acl SSL_ports port 443 acl Safe_ports port 21 80 443 70 210 280 488 591 777 1025-65535 acl CONNECT method CONNECT #access-sektion http_access allow manager localhost http_access deny manager http_access deny !Safe_ports http_access deny CONNECT !SSL_ports http_access allow localhost http_access deny all icp_access deny all htcp_access deny all
Allgemein
http_port 3128
Auf diesem Port lauscht der Squid auf eingehende http-Anfragen der Clients.
icp_port 3130
Auf diesem Port lauscht Squid auf eingehende Anfragen von Nachbar-Proxys
access_log /var/log/squid3/access.log squid
Legt Ort und Art des Loggings für eingehende Requests fest.
coredump_dir /var/spool/squid3
Standardmäßig schreibt Squid corefiles in das Verzeichnis aus dem er gestartet wurden. Wenn mit dieser Option ein Pfad angegeben ist, wechselt Squid nach dem Start in dieses Verzeichnis und legt die corefiles in dieses Verzeichnis ab.
hierarchy_stoplist cgi-bin ?
Hiermit wird eine Liste von Ausdrücken festgelegt, die - wenn sie in dem angefragen URL corkommen - Squid veranlassen, die Anfrage direkt auszuführen und keine Nachbar-Proxys zu befragen
Refresh_pattern
#refresh_pattern Suchmuster Min Prozent Max refresh_pattern ^ftp: 1440 20% 10080 refresh_pattern ^gopher: 1440 0% 1440 refresh_pattern (cgi-bin|\?) 0 0% 0 refresh_pattern . 0 20% 4320
Hier kann der Refresh-Algorithmus von squid für die eigenen Bedürfnisse optimiert werden.
MIN ist die Zeit in Minuten,die ein Objekt ohne explizite Ablaufzeit als Aktuell betrachtet wird. Der ermpfohlene Wert ist 0, jeder höhere Wert könnte dazu führen, dass dynmaische Anwendungen irrtümlich gecachtt werden, wenn der Webdesigner keine entsprechenden Gegenaktionen getroffen hat.
PROZENT ist der Prozentsatz eines Objektalters (Zeit seit der letzten Modifikation) wo ein Objekt ohne explizite Ablaufzeit als aktuell betrachtet wird.
MAX ist ein oberes Limit wie lange Objekte ohne explizite Ablaufzeiten als aktuell betrachtet werden.
refresh_pattern -i
Wie refresh_pattern, nur, daß Musterangaben die Groß-/Kleinschreibung ignorieren.
ACL
Unter ACL versteht man access control lists, also Filter, die den Zugriff auf den Proxy regeln. Eine ACL muss immer zuerst definiert werden und ein Name gegeben werden. ACLs werden in der Form
acl aclname acltyp argument ... acl aclname acltyp "datei"
definiert.
Beispielkonfiguration
In der Standardkonfiguration sind 6 ACLs definiert:
Standard- acl für Management-Dienste
acl manager proto cache_object
Alles was von localhost (also lokal über das loopback-device) kommt
acl localhost src 127.0.0.1/32
Alles was an localhost geht
acl to_localhost dst 127.0.0.0/8
acl für SSL_ports (Standard https-port)
acl SSL_ports port 443
acl für "sichere Ports"
acl Safe_ports port 80 (21,443,70,...)
acl CONNECT method CONNECT
Nachdem die ACLs definiert sind, müssen diese in Regeln angewendet werden. Die Syntax lautet:
regeltyp allow|deny [!acl1] [!acl2]
Eine Regel besagt also, dass ein Zugriff, der auf eine bestimmte Access-List zutrifft, entweder erlaubt (allow) oder verboten wird (deny).
In der Beispielkonfiguration werden http_access und icp-, htcp_access als Regeltyp angewendet, zB.
http_access allow localhost
wendet die Access-Liste 'localhost' an, um den lokalen Zugriff vom Proxy-Server auf http-seiten zu regeln. icp_access und htcp_access bzw. icp und htcp sind Protokolle für den Datenaustausch zwischen zwei Servern.
Eigene Erweiterungen
Die Konfiguration können wir jetzt erweitern und auf die Bedürfnisse des jeweiligen Netzwerks anpassen. Als Beispiel verwenden wir ein Netzwerk, welches 2 Subnetze enthält, die über einen Proxy, welcher in einer DMZ steht, Verbindungen zum Internet aufbaut. Das 192.168.241.0/24-Netz soll ein privilegiertes Netz sein, d.h Die Clients haben generell mehr Rechte um auf das Internet zuzugreifen, als das andere Netz (192.168.242.0/24).
Als Erstes wollen wir das eine Netz vorläufig komplett für den HTTP-Verkehr freischalten:
ACL für das Netz aufstellen:
#acl-sektion acl privilegiert src 192.168.241.0/24
ACL anwenden und das Netz freischalten:
#access-sektion http_access allow privilegiert
Die beiden Konfigurationsanweisungen müssen nun an korrekter Stelle in die squid.conf eingetragen werden. Bei der ACL ist das nicht so relevant, jedoch zur Übersichtlichkeit wird man sie in den Block mit den anderen ACLs einfügen. Bei der Access-Regel dagegen ist es dagegen von entscheidender Bedeutung, wo die Anweisung steht, da die Konfigurationsdatei von oben nach unten abgearbeitet wird und die erste Regel auf die eine Anfrage passt, wird ausgeführt.
#access-sektion http_access allow manager localhost http_access deny manager http_access deny !Safe_ports http_access deny CONNECT !SSL_ports http_access allow localhost http_access deny all http_access allow privilegiert
Wird die Regel wie hier angezeigt eingefügt, hat das keine Auswirkung auf den Zugriff, da die Regel "http_access deny all" vorher steht, welche auf alles zutrifft und so die Anfrage abweist. Also müssen wir die Regel weiter oben einfügen.
#access-sektion http_access allow manager localhost http_access deny manager http_access deny !Safe_ports http_access deny CONNECT !SSL_ports http_access allow localhost http_access allow privilegiert http_access deny all
Das unprivilegierte Netz soll nun auch Zugriff auf das Internet erhalten, jedoch nur in eingeschränktem Maße. Es soll nur auf den für den Arbeitsablauf notwendigen Webseiten Zugriff erhalten. Dies wird so realisiert, dass eine Datei mit Regex-URLs eingerichtet wird, auf die zugegriffen werden darf.
#acl-sektion acl unprivilegiert src 192.168.242.0/24 acl gute_domains url_regex -i "/etc/squid3/gute_domains" #access-sektion http_access allow unprivilegiert gute_domains
Diese Regel hat 2 acls als Argumente. Diese werden in den Access-Regeln durch ein UND verknüpft, d.h. die Regel matcht nur wenn beide acls zutreffen.
Nun wird eine Regel erstellt, damit URLs, auf die niemand zugreifen darf, im gesamten Netzwerk, also in den beiden Subnetzen, verboten wird.
#acl-sektion acl lan src 192.168.241.0/24 192.168.242.0/24 acl schlechte_domains url_regex -i "/etc/squid3/schlechte_domains" #access-sektion http_access deny lan schlechte_domains
root@zero:/etc/squid3# cat schlechte_domains ^http://(www.)?pornographische-seite1.de ^http://(www.)?boese-seite2.com root@zero:/etc/squid3#
Hier wird eine ACL erstellt, die 2 Argumente besitzt. Diese werden, im Gegensatz zu den Access-Regeln, mit einem ODER verknüpft, sodass diese Regel matcht, falls eine Anfrage der beiden Subnetze als Source mit einer URL aus der Datei "schlechte_domains" kommt. In Aussagenlogikform:
lan = ( privilegiert ODER unprivilegiert ) acl = lan UND schlechte_domains
Jetzt wollen wir z.B den Nutzern im unprivilegierten Netz auch die Möglichkeit geben, während der Mittagspause frei im Internet surfen zu können. Dazu benutzt man den acl-Typ "time":
#acl-sektion acl mittag time 12:00-12:30 #access-sektion http_access allow unprivilegiert mittag
Hier wird eine acl mittag definiert, die einen Zeitbereich annimmt. Diese wird mit der acl unprivilegiert in einer Regel verknüpft.
Authentifizierung
Passwortdatei
Mit dem Programm htpasswd (ruft Systemfunktion crypt auf )das bei jeder Distribution dabei sein sollte können ein Passwortdatei erzeugen.
root@zero:/etc/squid3# htpasswd -c passwd xinux New password: Re-type new password: Adding password for user xinux root@zero:/etc/squid3# cat passwd xinux:5AZTQ/gAwdlOU root@zero:/etc/squid3#
Konfigurationsdatei
#auth-sektion auth_param basic program /usr/lib/squid3/ncsa_auth /etc/squid3/passwd auth_param basic children 5 auth_param basic concurrency 0 auth_param basic realm Squid proxy-caching web server auth_param basic casesensitive off #acl-sektion acl autorisiert proxy_auth REQUIRED #access-sektion http_access allow unprivilegiert autorisiert
In der Konfigurationsdatei wird nun ein Programm angegeben, das für die Authentifizierung aufgerufen wird. Dieses liest Daten aus der zuvor angefertigten Passwortdatei. Dann muss eine acl mit dem typ "proxy_auth" erstellt werden, welche in einer Regel angewendet wird. So kann hier auch ein Nutzer aus dem unprivilegierten Netz Zugang zum Internet bekommen, sollte er sich authentifizieren können.
Caching
Squid benutzt den Hauptspeicher und ein Verzeichnis, um Anfragen zu cachen und diese bei erneuten Anfragen direkt auszuliefern.
Anlegen des Caches
root@zero:/etc/squid3# cd /var/cache/ root@zero:/var/cache# mkdir squid root@zero:/var/cache# chown proxy:proxy squid/ root@zero:/var/cache# ls -l | grep squid drwxr-xr-x 2 proxy proxy 4096 2009-07-10 09:53 squid
Hier wird ein Verzeichnis angelegt, welches dem Benutzer proxy beschreibbar sein, da der Squid nicht unter root, sondern unter einem unprivilegierten Benutzer läuft.
#cache-sektion cache_dir ufs /var/cache/squid 100 16 256
cache_dir typ verzeichnis MB L1 L2
In der Konfigurationsdatei wird dieses Verzeichnis angegeben. Der Typ "ufs" ist das Standardspeichersystem des Squid. Es können aber auch andere Typen wie aufs oder diskd benutzt werden. Die Optionen hinter dem Verzeichnisnamen, geben Speicherplatz und Verzeichnisstruktur an. MB gibt an, wieviel Speicherplatz Squid in diesem Verzeichnis benutzt (es können auch mehrere Verzeichnisse zur Speicherverteilung auf verschiedene Partitionen angegeben werden), L1 gibt an wieviele First-Level-Unterverzeichnisse angelegt werden, L2 gibt an, wieviele Second-Level-Unterverzeichnisse in jedem First-Level-Verzeichnis angelegt werden (Baum-Struktur).
root@zero:/var/cache# /etc/init.d/squid3 restart
* Restarting Squid HTTP Proxy 3.0 squid3
* Waiting...
* ...
* ...
* ...
* ...
* ...
* ... [ OK ]
* Creating Squid HTTP Proxy 3.0 cache structure
2009/07/10 09:59:24| Creating Swap Directories
2009/07/10 09:59:24| /var/cache/squid exists
2009/07/10 09:59:24| Making directories in /var/cache/squid/00
2009/07/10 09:59:24| Making directories in /var/cache/squid/01
2009/07/10 09:59:24| Making directories in /var/cache/squid/02
2009/07/10 09:59:24| Making directories in /var/cache/squid/03
2009/07/10 09:59:24| Making directories in /var/cache/squid/04
2009/07/10 09:59:24| Making directories in /var/cache/squid/05
2009/07/10 09:59:24| Making directories in /var/cache/squid/06
2009/07/10 09:59:24| Making directories in /var/cache/squid/07
2009/07/10 09:59:24| Making directories in /var/cache/squid/08
2009/07/10 09:59:24| Making directories in /var/cache/squid/09
2009/07/10 09:59:24| Making directories in /var/cache/squid/0A
2009/07/10 09:59:24| Making directories in /var/cache/squid/0B
2009/07/10 09:59:24| Making directories in /var/cache/squid/0C
2009/07/10 09:59:24| Making directories in /var/cache/squid/0D
2009/07/10 09:59:24| Making directories in /var/cache/squid/0E
2009/07/10 09:59:24| Making directories in /var/cache/squid/0F
[ OK ]
root@zero:/var/cache/squid# ls
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F swap.state
root@zero:/var/cache/squid# cd 00
root@zero:/var/cache/squid/00# ls
00 0E 1C 2A 38 46 54 62 70 7E 8C 9A A8 B6 C4 D2 E0 EE FC
01 0F 1D 2B 39 47 55 63 71 7F 8D 9B A9 B7 C5 D3 E1 EF FD
02 10 1E 2C 3A 48 56 64 72 80 8E 9C AA B8 C6 D4 E2 F0 FE
03 11 1F 2D 3B 49 57 65 73 81 8F 9D AB B9 C7 D5 E3 F1 FF
04 12 20 2E 3C 4A 58 66 74 82 90 9E AC BA C8 D6 E4 F2
05 13 21 2F 3D 4B 59 67 75 83 91 9F AD BB C9 D7 E5 F3
06 14 22 30 3E 4C 5A 68 76 84 92 A0 AE BC CA D8 E6 F4
07 15 23 31 3F 4D 5B 69 77 85 93 A1 AF BD CB D9 E7 F5
08 16 24 32 40 4E 5C 6A 78 86 94 A2 B0 BE CC DA E8 F6
09 17 25 33 41 4F 5D 6B 79 87 95 A3 B1 BF CD DB E9 F7
0A 18 26 34 42 50 5E 6C 7A 88 96 A4 B2 C0 CE DC EA F8
0B 19 27 35 43 51 5F 6D 7B 89 97 A5 B3 C1 CF DD EB F9
0C 1A 28 36 44 52 60 6E 7C 8A 98 A6 B4 C2 D0 DE EC FA
0D 1B 29 37 45 53 61 6F 7D 8B 99 A7 B5 C3 D1 DF ED FB
root@zero:/var/cache/squid/00#
Hier sieht man, das Squid im Verzeichnis /var/cache/squid 16 Verzeichnisse von 00-0F und in jedem Unterverzeichnis weitere 256 Verzeichnisse 00-FF angelegt hat.
Konfiguration
Nun können weitere Optionen in der Konfigurationsdatei angegeben werden.
cache_mem 32 MB
Gibt an, wieviel Hauptspeicher zum Cachen für Squid verwendet wird
cache_swap_low 90 cache_swap_high 95
Diese beiden Optionen geben den unteren und oberen Threshold für die Füllung des Caches an in % an. Wird die untere Marke überschritten, beginnt Squid entsprechend der cache_replacement_policy Objekte aus dem Cache zu entfernen. Wird die obere Marke erreicht, erfolgt die Räumung aggressiver. Wird die untere Marke unterschritten, wird der Prozess beendet.
minimum_object_size 0 KB maximum_object_size 8192 KB
minimum_object_size gibt an, wie groß ein Objekt mindestens sein muss, um im Cache gespeichert zu werden, maximum_object_size die maximale Größe.
maximum_object_size_in_memory 64 KB
maximum_object_size_in_memory gibt an, wie groß ein Objekt höchstens sein darf, um im Hauptspeicher gecacht zu werden.
ipcache_size 1024
Hier wird die maximale Anzahl der IP-Cache Einträge bestimmt.
ipcache_low 90 ipcache_high 95
Thresholds der IP-Cache-Einträge, entsprechend zu cache_swap_low und _high.
fqdncache_size 1024
Maximale Anzahl der FQDN-Cache-Einträge.
cache_replacement_policy lru memory_replacement_policy lru
Diese Einträge bestimmen, mit welchem Verfahren Objekte aus dem Cache entfernt werden. lru steht für least recently used, d.h. Squid löscht bei diesem Verfahren die Einträge, die am längsten nicht mehr angefragt wurden. Es gibt außerdem:
heap GDFS (Greed-Dual Size Frequency): Optimiert die Objekt-Hitrate. Kleine häufig angefragte Objekte werden auf Kosten großer, weniger häufig angefragter Objekte im Cache gehalten. Damit wird die Warscheinlichkeit eines Objekt-Hits gesteigert.
heap LFUDA (Least frequently used with dynamic aging): Optimiert die Byte-Hitragte. Häufig angefrage Objekte werden im Cache gehalten, slten angefragte Objekte werden freigegeben, unabhängig von deren Größe. Damit wird ein häufiger angefrages, großes Objekt ggf. auf Kosten vieler kleiner Objekte im Cache gehalten.
heap lru (erweitertes lru-Verfahren).
Delay-Pools
Mit Delay-Pools kann man eine Bandbreitensteuerung über Squid implementieren.
#delay_pools-sektion delay_pools 2
Hier wird die Anzahl der Pools angegeben.
#delay_claas pool class delay_class 1 1 delay_class 2 2
Jeder der Pools wird einer Klasse zugeordnet. Es gibt insgesamt 5 Klassen, die verschiedene Methoden zur Bandbreitensteuerung anbieten.
Klasse 1: Die gesamte Bandbreite wird über ein Parameterpaar gesteuert.
Klasse 2: Es werden 2 Parameterpaare angegeben. Das erste bestimmt die gesamte Bandbreite, das zweite bestimmt die individuelle Bandbreite eines Hosts anhand des letzten Bytes der IP-Adresse.
Klasse 3: Zusätzlich zu den 2 Parametepaaren in Klasse 2 gibt es noch ein drittes Paar, welches die Bandbreite eines ganzen Klasse-C-Netzes beschränkt.
Klasse 4: Wie Klasse 3, jedoch gibt es noch ein zusätzliches Parameterpaar, welches anhand des Benutzernamens die Bandbreite beschränkt. Diese Limitierung tritt nur in Kraft, sollte ein Request eine Benutzerauthentifizierung erfordert haben (siehe Authentifizerung).
Klasse 5: Die Bandbreitenregulierung erfolgt nicht wie in Klasse 2-4 über IP-Adressen oder Benutzer, sondern über ein Tag, welches angegeben wird und einen Request identifiziert.
delay_parameters 1 10000/20000 delay_parameters 2 20000/40000 1000/2000 delay_access 1 allow privilegiert delay_access 2 allow unprivilegiert delay_access 1 deny all delay_access 2 deny all
Nun müssen den Delay-Pools noch die Parameter übergeben werden. Der Delay-Pool mit Klasse 1 erhält ein Parameterpaar. Dieses Parameterpaar setzt sich zusammen aus restore- und einem maximum-Wert. Der restore-Wert bestimmt die eigentliche Bandbreite in Byte/Sekunde, der maximum-Wert bestimmt die maximale Datenmenge in Byte, die auf einmal übertragen wird.
Die mit maximum definierte Datenmenge wird ganz normal über das Netz übertragen, ggf. mit der vollen zur Verfügung stehenden Bandbreite und ohne weitere Begrenzung. Anhand des eigentlichen Bandbreitenwertes restore berechnet Squid, wie lange er das nächste Paket verzögern muss, um auf die durchschnittliche, mit restore vorgegebene Bandbreite zu kommen. So wird die vorgegebene Nettobandbreite im Mittel durchaus gehalten, ein einzelnes Datenpaket kann jedoch deutlich schneller zum Client transportiert werden.
Mit delay-access wird nun festelegt, welche Pools auf welche acl angewendet werden.